Converting from Speech to Text with JavaScript
In this tutorial we are going to experiment with the Web Speech API. It's a very powerful browser interface that allows you to record human speech and convert it into text. We will also use it to do the opposite - reading out strings in a human-like voice.
Let's jump right in!
The App
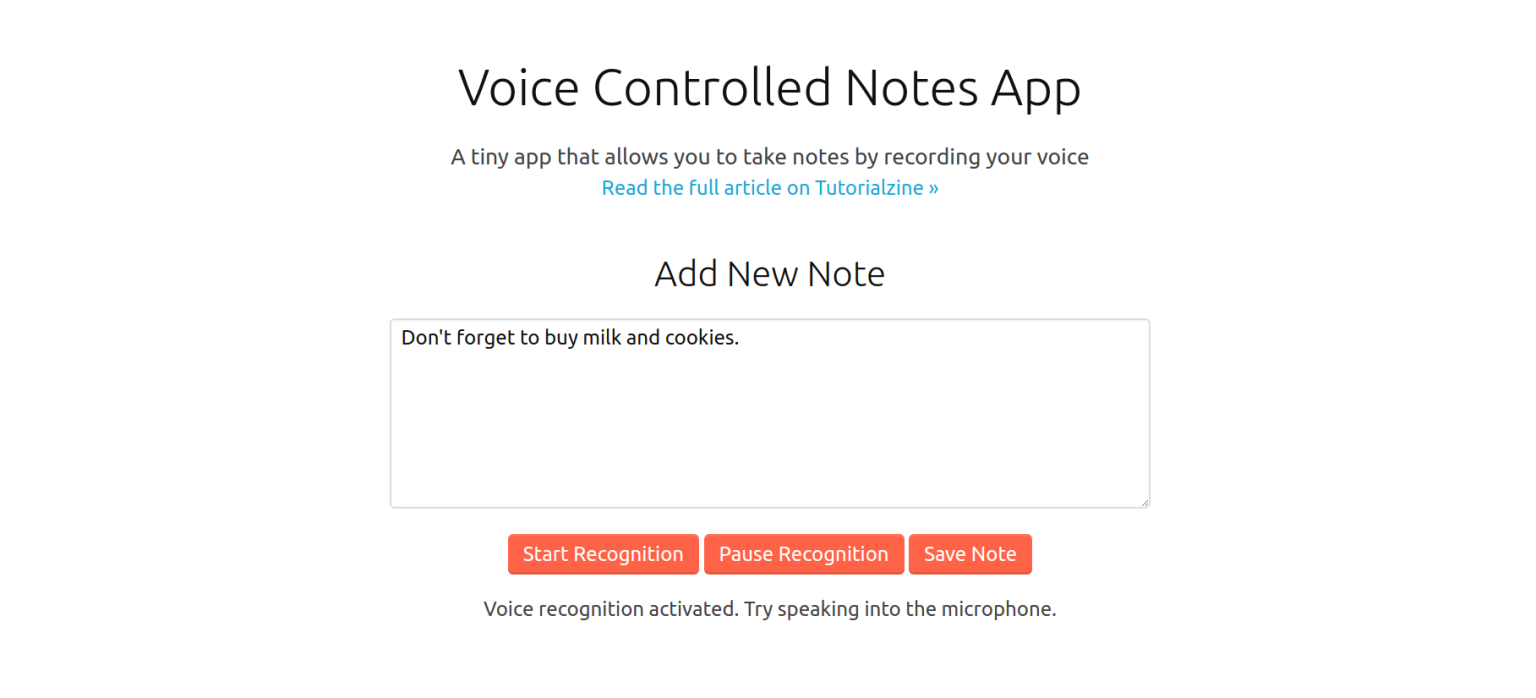
To showcase the ability of the API we are going to build a simple voice-powered note app. It does 3 things:
- Takes notes by using voice-to-text or traditional keyboard input.
- Saves notes to localStorage.
- Shows all notes and gives the option to listen to them via Speech Synthesis.
We won't be using any fancy dependencies, just good old jQuery for easier DOM operations and Shoelace for CSS styles. We are going to include them directly via CDN, no need to get NPM involved for such a tiny project.
The HTML and CSS are pretty standard so we are going to skip them and go straight to the JavaScript. To view the full source code go to the Download button near the top of the page.
Speech to Text
The Web Speech API is actually separated into two totally independent interfaces. We have SpeechRecognition for understanding human voice and turning it into text (Speech -> Text) and SpeechSynthesis for reading strings out loud in a computer generated voice (Text -> Speech). We'll start with the former.
The Speech Recognition API is surprisingly accurate for a free browser feature. It recognized correctly almost all of my speaking and knew which words go together to form phrases that make sense. It also allows you to dictate special characters like full stops, question marks, and new lines.
The first thing we need to do is check if the user has access to the API and show an appropriate error message. Unfortunately, the speech-to-text API is supported only in Chrome and Firefox (with a flag), so a lot of people will probably see that message.
try {
var SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
var recognition = new SpeechRecognition();
}
catch(e) {
console.error(e);
$('.no-browser-support').show();
$('.app').hide();
}
The recognition variable will give us access to all the API's methods and properties. There are various options available but we will only set recognition.continuous to true. This will enable users to speak with longer pauses between words and phrases.
Before we can use the voice recognition, we also have to set up a couple of event handlers. Most of them simply listen for changes in the recognition status:
recognition.onstart = function() {
instructions.text('Voice recognition activated. Try speaking into the microphone.');
}
recognition.onspeechend = function() {
instructions.text('You were quiet for a while so voice recognition turned itself off.');
}
recognition.onerror = function(event) {
if(event.error == 'no-speech') {
instructions.text('No speech was detected. Try again.');
};
}
There is, however, a special onresult event that is very crucial. It is executed every time the user speaks a word or several words in quick succession, giving us access to a text transcription of what was said.
When we capture something with the onresult handler we save it in a global variable and display it in a textarea:
recognition.onresult = function(event) {
// event is a SpeechRecognitionEvent object.
// It holds all the lines we have captured so far.
// We only need the current one.
var current = event.resultIndex;
// Get a transcript of what was said.
var transcript = event.results[current][0].transcript;
// Add the current transcript to the contents of our Note.
noteContent += transcript;
noteTextarea.val(noteContent);
}
The above code is slightly simplified. There is a very weird bug on Android devices that causes everything to be repeated twice. There is no official solution yet but we managed to solve the problem without any obvious side effects. With that bug in mind the code looks like this:
var mobileRepeatBug = (current == 1 && transcript == event.results[0][0].transcript);
if(!mobileRepeatBug) {
noteContent += transcript;
noteTextarea.val(noteContent);
}
Once we have everything set up we can start using the browser's voice recognition feature. To start it simply call the start() method:
$('#start-record-btn').on('click', function(e) {
recognition.start();
});
This will prompt users to give permission. If such is granted the device's microphone will be activated.
Most APIs that require user permission don't work on non-secure hosts. Make sure you are serving your Web Speech apps over HTTPS.
The browser will listen for a while and every recognized phrase or word will be transcribed. The API will stop listening automatically after a couple seconds of silence or when manually stopped.
$('#pause-record-btn').on('click', function(e) {
recognition.stop();
});
With this, the speech-to-text portion of our app is complete! Now, let's do the opposite!
Text to Speech
Speech Synthesys is actually very easy. The API is accessible through the speechSynthesis object and there are a couple of methods for playing, pausing and other audio related stuff. It also has a couple of cool options that change the pitch, rate, and even the voice of the reader.
All we will actually need for our demo is the speak() method. It expects one argument, an instance of the beautifully named SpeechSynthesisUtterance class.
Here is the entire code needed to read out a string.
function readOutLoud(message) {
var speech = new SpeechSynthesisUtterance();
// Set the text and voice attributes.
speech.text = message;
speech.volume = 1;
speech.rate = 1;
speech.pitch = 1;
window.speechSynthesis.speak(speech);
}
When this function is called, a robot voice will read out the given string, doing it's best human impression.
Conclusion
In an era where voice assistants are more popular then ever, an API like this gives you a quick shortcut to building bots that understand and speak human language.
Adding voice control to your apps can also be a great form of accessibility enhancement. Users with visual impairment can benefit from both speech-to-text and text-to-speech user interfaces.
The speech synthesis and speech recognition APIs work pretty well and handle different languages and accents with ease. Sadly, they have limited browser support for now which narrows their usage in production. If you need a more reliable form of speech recognition, take a look at these third-party APIs:
- Google Cloud Speech API
- Bing Speech API
- CMUSphinx and it's JavaScript version Pocketsphinx (both open-source).
- API.AI - Free Google API powered by Machine Learning
Bootstrap Studio
The revolutionary web design tool for creating responsive websites and apps.
Learn more
Comments 18
Excellent article and very easy to follow.
I got to thinking, why not add CKEditor to the textarea and did so after downloading demo. Everything looks good, even the recording works and notes can be saved. BUT, the spoken wrods are not appearing in the CKEditor area.
When you have time, could you possible cover getting your tutorial working with CKEditor? Be a really nice addition to have:)
Thanks for sharing your notes tutorial!
THIS IS MY CURRENT ISSUE RIGHT NOW. DID YOU SOLVED IT MAN ?
Great tutorial!
Just wondering why doesn't the Start Recognition button work if I copy the code to a Codeanywhere project?
excellent article. i didn't have idea that such API exists in browser. tried example in chrome , worked fine.
how this work for non-english speaking language?
Both text-to-speech and speech-to-text work pretty well with other languages.
For speech recognition you have to set the recognition.lang property.
With speech synthesis you can change the speaking voice. There is a large list of different languages to choose from - getVoices.
Sorry, it doesn't work.
It's problem with your secure connection. Check Is it https or not ?
This is working excellent on my local server i have implemented this and uploaded it on hosting server when i start the recognition the page says , this page is always blocked from using the microphone . Can you help me ?
i am working on speech recognition for Android applications. please suggest me can i use it in android and how can i get jar file for artyom.js?
Nice tutorial!
Is there a way to change language for the recognizer?
previously I had one already developed, but this one started to give me problems in the activation of the microphone, so I've been looking for solutions, I see that this example works very well, but when downloading the code and even make a copy and use the current one, it does not work for me, I put it on my server and nothing, so I tried to put it in a hosting to see if the server was the problem, and in the same way it does not connect, the microphone is not activated, which is what I will be missing for that this example works well, since I can not make functional the activation of the microphone, unless it enters by localhost, there is its that allows me to activate the microphone.
It's problem with your secure connection. Check Is it https or not ?
Firefox (with a flag) what about flag ?
It's working perfectly fine on Chrome... but, what changes we need to do so that it will work on all browsers..
Excellent articles and easy to understand and also easy to implement
why doesn't the Start Recognition button work if I copy the code in visual studio code ?
this is great 💥💥💥
great tutorial and library thank you so much for it, but actually i have problem when recognizing languages other than English have you made this library to work with other languages.
my case: i am trying to recognize Arabic and turn an Arabic speech to text but the Arabic written in English letters and that is not correct